

If you’re here because you want a primer in machine learning and artificial intelligence, then you’ve definitely come to the right place. Today, we’re going to cover the fundamentals of this emerging technology. You might be wondering: What are these fundamentals you speak of?
Simple. First, we’re going to unpack the field’s biggest buzzwords and get you talking like a machine learning scientist. Next, we’ll get into the nitty gritty of how AI is actually being operationalized today. Finally, we’re going to break down the most straightforward machine learning method in existence—linear regression—with a real-life example.
Machine learning buzzwords you need to know right now
Artificial general intelligence (AGI)
When people think of artificial intelligence, they typically envision HAL 9000, or if you don’t get that reference, how about The Matrix? The Terminator? These are the cinematic examples of AGI, artificial general intelligence, machines that can mimic virtually anything a human can do.
Artificial narrow intelligence (ANI)
Today, when most companies talk about AI, they’re referring to artificial narrow intelligence. We’re talking self-driving vehicles, chatbots, smart assistants or that Netflix algorithm that recommends that you binge-watch Tiger King this weekend. ANI systems can learn to perform a very specific task, but ask it to make you a cup of coffee, pick up your dry cleaning, then filter out your junk mail, and it’s not even going to understand the problem.
Machine learning (ML)
One of the most promising disciplines of artificial intelligence, for practical use, is machine learning.
In the words of Arthur Samuel, machine learning is a “field of study that gives computers the ability to learn without being explicitly programmed.”
That’s right, instead of programming a machine with a specific set of instructions, or rules, you show it some input data and what the corresponding output should be (this is the learning part), then you unleash it on new inputs to predict what it thinks the results are.
A classic example is email spam filtering. The Gmail spam filter has been trained on millions of emails and has learned what looks legit and what should be tossed. The iterative process of learning fine tunes models to the point where they can generate amazingly accurate predictions.
Google says its machine learning tech now blocks 99.9% of Gmail spam and phishing messages.
Features
Let’s look back to our email spam filter example from above by looking at the features of an email. They could include things like how often certain words or phrases appear. How long the email is. The background color. Some features are useful when it comes to predicting whether an email is spam or not, like certain words in the subject line, while others might not be.
Labels
A label is the thing we are predicting. For spam filtering, there are two labels:
- Not spam, in which case: Yay!
- Spam, in which case: Boo! (by the way, this is what we call a simple binary classification)
Straightforward, right?
Samples
Samples are particular instances of data that can be used to train a model. Think back to all those times you marked an email as spam. You were helping to label and therefore train the spam filter with your email sample. The more you know.
The three flavors of ML
Machine learning is a little like Neapolitan ice cream—colourful, cool, and it comes in three flavours. You’ve got supervised learning, AKA your basic vanilla; unsupervised learning, your bold chocolate; and my personal favorite, reinforcement learning—with real strawberry pieces!
Okay, now that your stomach’s grumbling, let's take a bite out of each flavour.
A taste of vanilla: supervised learning
Supervised learning is straightforward. Thanks to our spam example above, you already have an idea of how it works. With supervised learning, a model is trained on labelled data (emails that have already been flagged as spam and those that haven’t), and shown data it has never seen before (new emails) to make a prediction. Along with the spam filter, recognizing images and predicting the price a house will sell for are real-life applications of supervised learning. If you want to dig deeper, check out what regression and classification problems are all about.
Now, for the chocolate: unsupervised learning
Unsupervised learning involves looking for patterns in data and finding groups of data points that are similar and others that are outliers. The data is unlabelled and it typically isn’t easy to find a good way to group data points by hand. That’s where unsupervised learning shines, by trying to make sense of information that a human wouldn’t be able to see.
For example, if you want to group customers based on their buying traits but don’t know what those traits are, you could use unsupervised learning to cluster similar customers together. Subsequently, you can use those clusters to better understand your customer’s behaviour.
A lil bit of strawberry: reinforcement learning
Have you heard about how humans are no longer a match for AI in the game of Go? Or how the strongest traditional chess engine has gotten dismantled by AI? Then you’ve tasted the power of reinforcement learning at work.
Reinforcement learning operates a little differently than our vanilla and chocolate flavors. Rather than learning from labelled or unlabelled data, an RL agent (imagine a little virtual robot) learns about a dynamic environment by taking actions and receiving a positive or negative reward. The actions that lead to more positive outcomes are the ones it tries to replicate.
Let's take my son for example. He loves ice cream (duh!) and his objective is to maximize the scoops he gets over the next year. He can try various actions like:
- Stomp his feet and demand ice cream;
- Try to bribe us with lego blocks;
- Ask very nicely, or;
- Clean his room and complete his homework
Each action will yield a different reward and over time he will learn which actions give him the best chance of achieving his goal. Sometimes, he will get no ice cream and sent to his room if he tries to demand ice cream or he could get two scoops if he cleans up and does his worksheets.
Now, my son might actually have many more actions he can try out until he finds the 'best' one that he can begin to take full advantage of. That process of trying new actions, while still getting a consistent flow of ice cream is the tradeoff between exploration and exploitation that an RL agent needs to balance.
integrate.ai uses a mixture of all three machine learning flavors, although we’re particularly focused on reinforcement learning, as it has given us a leg up in understanding consumer behaviour.
My linear regression obsession
All this talk of ice cream has me hungry, so let's wrap this up with an example that illustrates how a simple machine learning model can be used to find a relationship between a father’s height and his son's height. I really, really want to use tigers in this example, but alas, I don't have any tiger data available.
The algorithm we'll use is called linear regression, one of many techniques out there and an easy place to start. If you've heard of linear regression before you're probably thinking: "I know what that is, how can that be machine learning?!".
Well, the basic ideas in machine learning have been around for a while but there were barriers to practical use. Some of the reasons this technology has exploded over the last few years is because we now have the computing power and quantity of data necessary to take full advantage of it. And I should mention there have been advances in the field of neural networks that have produced compelling results. We'll jump into the deep end on that in a later blog though, so stay tuned.
Let's start with the data. Below are sample data points showing the heights of father and son and what they look like plotted. We’ll use this data to train our model.

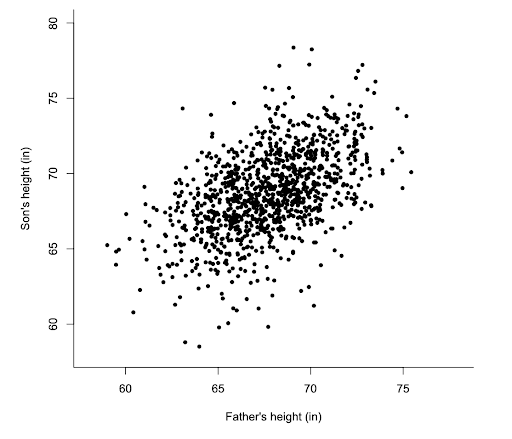
You’ll notice the only feature in our model that’s being used to predict the son's height is the father's height. As you can imagine, there are many additional features that could increase the accuracy of the son's height prediction. The mother's height, the race of both parents, how much sleep the kid gets, even his weekly average ice cream consumption. We are keeping it simple so we can visualize things but the concepts are the same, only with more features.
We want to find a useful representation of the dataset. That is, we want to find a mathematical equation to relate the output (son's height) with the input (father's height). Here’s where we get mathy. The function used in linear regression is that of a straight line:
y = mx + b
Let’s break the function down:
- y is what we are trying to predict; in other words, the son’s height
- x is a feature we are using to make a prediction; in other words, the father’s height
- m describes how steep the line is
- b describes where the line crosses the y-axis

As you can imagine, there are countless lines we could draw through the data, but how do you find the best one? (Hint: It’s the line that minimizes the error in the prediction of the son’s height with the actual height, across all training samples.) What do I mean by ‘find the best line’? Well, that just means finding the right m and b parameters. How do we minimize error?
Here comes our second and final function of the day:

What this loss function is saying is that the error in our guess at the line of best fit is the average of the sum of the squared difference between the predicted and actual values of the son’s height.
I know that was a mouthful, so let’s visualize it for clarity:

The red line is one guess at our best fit line. For each datapoint the line predicts the son’s height but the black dot is the actual height and is not necessarily on the line. The difference between a particular dot and the red line is the prediction error. For example, in the second datapoint from the left, you can see the actual value is 5 and our model predicts 15, so the error is 10. You can essentially add up all those individual errors to tell how good or bad the line is. (Technically you are squaring the difference, summing and then finding the mean.)
The idea is to try many different lines (different m and b values) to find the one with the lowest error. The machine learning algorithm starts with a random guess, but then uses a methodical process to guide it to the final solution. Check out gradient descent if you want to learn more.
And that’s that! The linear regression algorithm will converge on the line of best fit and the function might look something like this:
y = 0.95x + 4.8
Now comes the cool part, we can feed the model the height of any father (x) and get a prediction of what their son’s height is (y). For example if you have a father who is 70 inches tall, our model predicts the son’s height will be 71.3 inches (0.95 x 70 + 4.8).
Pretty neat, eh?
As always, if you have any questions or are just looking to talk shop, feel free to get in touch. To take a look at our #ML4EVERY1 syllabus, click here.

